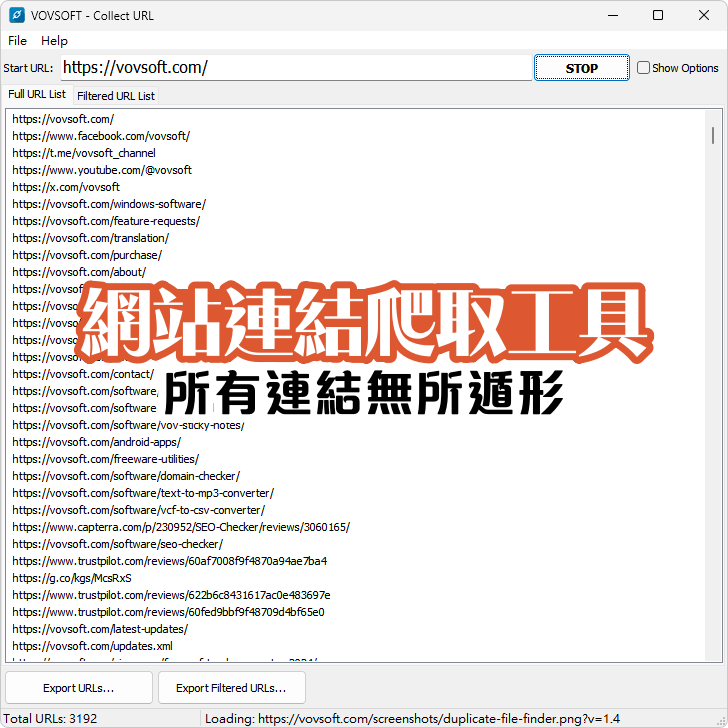
爬蟲整個網站
2020年10月26日—本项目旨在教你如何构建一个基础的Python爬虫,以爬取任意网页内容。我们将以爬取某网站首页为例,但你完全可以根据需要调整代码来适应其他目标网站。,簡單來說,網頁爬蟲就是可以模仿人類瀏覽器行為,自動抓取網頁資訊的程式。利用這種程式的自動化...
[Python爬蟲教學]7個Python使用BeautifulSoup開發網頁 ...
- 網頁爬蟲工具
- 線上爬蟲
- 不用 寫程式 爬蟲
- 免費爬蟲軟體
- google script爬蟲
- 爬蟲整個網站
- 線上爬蟲
- 爬蟲網站推薦
- python爬蟲工具
- import io
- kimono下載
- 網路爬蟲合法
- kimono api
- 線上爬網站
- 下載網路資料
- python抓網頁表格
- 爬 文 工具
- email爬蟲
- kimono爬蟲
- 網路爬蟲服務
- 解析網頁
- 下載整個網站
- 網頁數據
- 爬蟲程式java
- listly下載
BeautifulSoup是一個用來解析HTML結構的Python套件(Package),將取回的網頁HTML結構,透過其提供的方法(Method),能夠輕鬆的搜尋及擷取網頁上所需的資料,因此廣泛的應用在 ...
** 本站引用參考文章部分資訊,基於少量部分引用原則,為了避免造成過多外部連結,保留參考來源資訊而不直接連結,也請見諒 **


