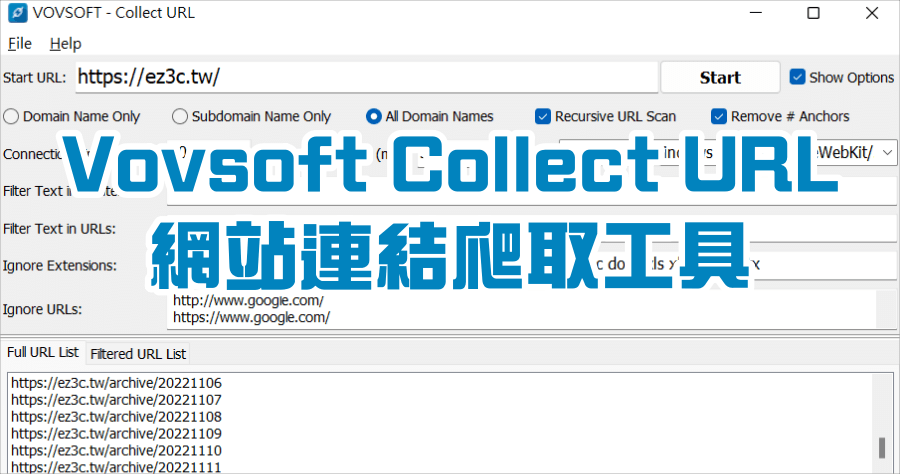
爬取網址
...爬取的頁面規範,可至該網站網域/robots.txt查看,如https://www.facebook.com/robots.txt及https://twitter.com/robots.txt。都有寫明禁止爬取之處。robots ...,WebHarvy是一個點擊式網頁抓取軟件。它專為非程序員設計。WebHarvy可以自動從網站上抓取文本,圖像...
以上就是Python網頁爬蟲在遇到有分頁的網站時,能夠動態換頁爬取網頁內容的實作方式,詳細的程式碼可以參考下方的GitHub網址,希望有幫助到大家。如果您喜歡我的文章,請 ...
** 本站引用參考文章部分資訊,基於少量部分引用原則,為了避免造成過多外部連結,保留參考來源資訊而不直接連結,也請見諒 **
Day 24 : Python 常用網路資料擷取術
... 爬取的頁面規範,可至該網站網域 /robots.txt 查看,如 https://www.facebook.com/robots.txt 及 https://twitter.com/robots.txt 。都有寫明禁止爬取之處。 robots ...
20個網頁抓取工具快速抓取網站
WebHarvy是一個點擊式網頁抓取軟件。它專為非程序員設計。 WebHarvy可以自動從網站上抓取文本,圖像,網址和電子郵件,並以各種格式保存抓取的內容。它還提供內置的調度 ...
網路爬蟲:數據資料的爬取
1、request模組: 讀取網站資料¶. requests模組可以用Python程式發出HTTP的請求,取得指定網站的內容。 (requests模組使用前必須先安排,在Anaconda中已內建). 練習網頁.
網頁擷取技巧
在抓取網頁資料的時候,如果像是上述的例子,同樣的資訊有超過一頁的內容需要擷取,只要分析網址的特色(也就是後面的查詢命令的規則和用法),抓取時再加以組合即可。
認識網路爬蟲:解放複製貼上的時間
2023年8月31日 — 是一個可以自動化抓取網頁內容的程式。 相信大家多少都遇過需要抓取網頁資訊的時候,也許是因為要做報告、或是出於興趣想研究,需要相關參考資料。最 ...
【Python學堂】新手入門第十二篇
2022年8月5日 — 爬取ezTravel網站的瘋台灣頁面 · 1. 分析網頁. 1_1. 取得網址(連結). 1_2. 取得主架構資訊. 爬取ezTravel網站的瘋台灣頁面-2 · 2. 下載網頁. 使用requests.