你需要將現有的影片翻譯成其他語言,並且直接輸出上字幕,再加上配音嗎?最近小編發現一款超極強大的 AI 工具
VideoTrans ,可以做到上述的功能,能
將影片翻譯為指定的語言 ,自動產生並新增該語言的字幕和配音。語音辨識使用 faster-whisper、openai-whisper 離線模型,文字翻譯支援 microsoft、google、baidu、tencent、chatGPT、Azure、Gemini、DeepL、DeepLX、離線翻譯 OTT,完全免費使用,推薦常處理影片的朋友可以收下這款神器喔。
各位可以先到文章最後方的載點下載本次的軟體,解壓縮檔大概是 1.82 GB。
解壓縮之後,大小總共超過 5GB,各位記得將壓縮檔解壓縮在全英文的路徑下,否則可能會沒有辦法執行。解壓縮完成之後,點上圖中的 SP 圖示來啟動應用程式,如果你點擊下去發現沒有反應,可能要等待一段時間之後才會啟動。
看到上方的畫面是正常的,因為是從非微軟官方商店下載的應用程式,就會出現上方的警告畫面,直接點擊仍要執行。
這個介面看起來有點可怕,不過其實沒有看起來得這麼複雜,下面小編一一為大家拆解。主要功能全部都在視窗左側,包含:
翻譯影片並配音:依需求設定各個選項,自由配置組合,實現翻譯和配音、自動加計量、合併等
辨識字幕不翻譯:選擇視訊文件,選擇視訊來源語言,則從視訊【語音辨識文字】並自動匯出字幕檔案到目標資料夾
字幕提取並翻譯:選擇視訊文件,選擇視訊來源語言,設定要翻譯到的目標語言,則從【視訊語音中辨識出文字】並翻譯為目標語言,然後匯出雙語字幕檔案到目標資料夾
字幕和影片合併:選擇影片,然後將現有的字幕檔拖曳到右側字幕區,將源語言和目標語言都設為字幕所用語言、然後選擇音配類型和角色,開始執行
為字幕建立配音:將本地的字幕檔拖曳到右側字幕編輯器,然後選擇目標語言、配音類型和角色,將產生配音後的檔案音訊到目標資料夾
音視頻辨識文字:將視訊或音訊拖曳到辨識窗口,將辨識出文字並匯出為srt字幕格式
將文字合成語音:將一段文字或字幕,使用指定的配音角色產生配音
從視訊分離音訊:將視訊檔案分離為音訊檔案和無聲視頻
音訊視訊字幕合併:音訊檔案、視訊檔案、字幕檔案合併為一個視訊文件
音訊視訊格式轉換:各種格式之間的相互轉換
文字字幕翻譯:將文字或 srt 字幕檔翻譯為其他語言
人聲背景樂分離:將影片中的人聲和背景音樂分別分離出來,產生2個音訊文件
下載油管視頻:可從 youtube 上下載視頻
首先點擊上方的選擇視頻來載入影片,然後右邊的「保存到」是儲存的路徑,先設定好這 2 個項目之後選擇「翻譯渠道」。預設是 Microsoft 翻譯引擎是免費的,所以我們用預設的 Microsoft 即可,如果你有 Google 或是 chatGPT,就需要額外的設定才可以使用。
接著我們選擇影片的原始語言,通常都是中文繁體,我們直接選擇中文繁體就可以了。
接下來是輸出的語言,如果你要把中文轉換成其他語言輸出語言,可以選擇簡繁、英語、韓語、西藏語、土耳其語、克拉克語、德語、土耳其語、西班牙語、支援葡萄牙語、越南語、泰國語、阿拉伯語、土耳其語、匈牙利語、印度語等等...,再來就是 TTS 語音轉文字的引擎,預設是 edge TTS,如果你有其他偏好,也可以選擇下方。一共有六種語音轉文字引擎。
配音也有支援繁體中文,繁中有 3 種不同的音色。配音指的是翻譯之後的配音,舉一個具體的例子,比如我的影片要中翻英,這個配音指的就是英文的聲音。
最後選擇 faster 模型或 openAI 模型,用預設的 faster 模型即可,然後再選擇 base、small、medium、large-v2、large-v3,越後面的選項,辨識效果越來越好,但辨識速度越來越慢,所需記憶體越來越大,內建 base 模型,其他模型請單獨下載後,解壓縮放到 /models 目錄下,如果 GPU 低於 4GB,請勿使用 large-v3
硬字幕是直接把辨識出來的字幕壓在影片上,軟字幕則是輸出 SRT 方便日後可以再編輯。
最後按下開始就會開始就會開始辨識字幕,如果你電腦有顯卡可以把 CUDA 加速勾起來,速度會快很多,否則用 CPU 去跑會比較吃力。等待一段時間後,就可以看到字幕辨識完成出現在右側囉。
接著打開我們剛剛指定的資料夾,就可以看到檔案,有影片檔、字幕檔、配音檔。效果放在下方給各位看看。
VIDEO
上方是小編載入的原始影片
VIDEO
這個是 AI 處理過後的影片,小編是直接中文改中文,繁中配音不錯,不會有中國腔調,不過影片的嘴型會對不上,因為嘴型沒有修改,但用來處理影片翻譯是滿快速的方案,而且是免費的,連結小編整理在下方,請立即收下試試吧!下載:
VideoTrans ( Guthub 下載 )
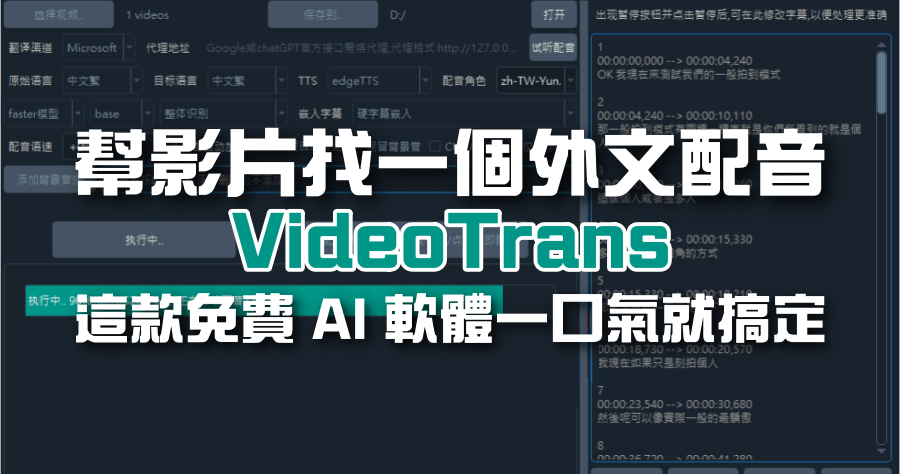
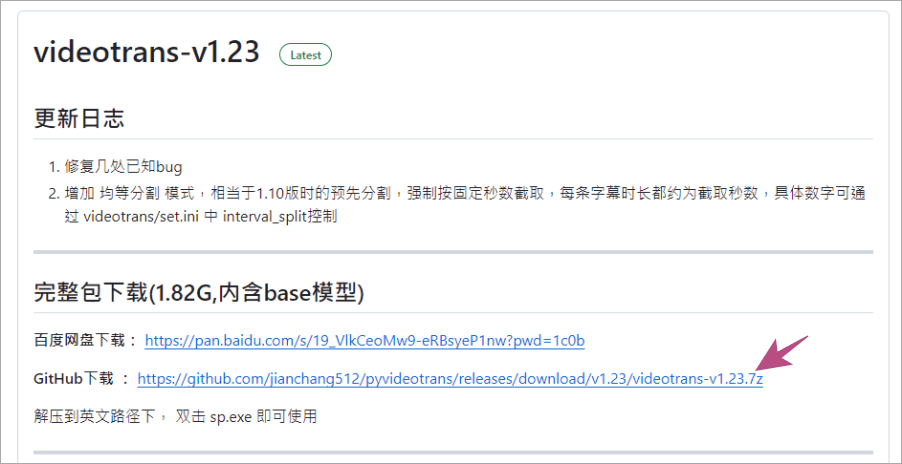 各位可以先到文章最後方的載點下載本次的軟體,解壓縮檔大概是 1.82 GB。
各位可以先到文章最後方的載點下載本次的軟體,解壓縮檔大概是 1.82 GB。 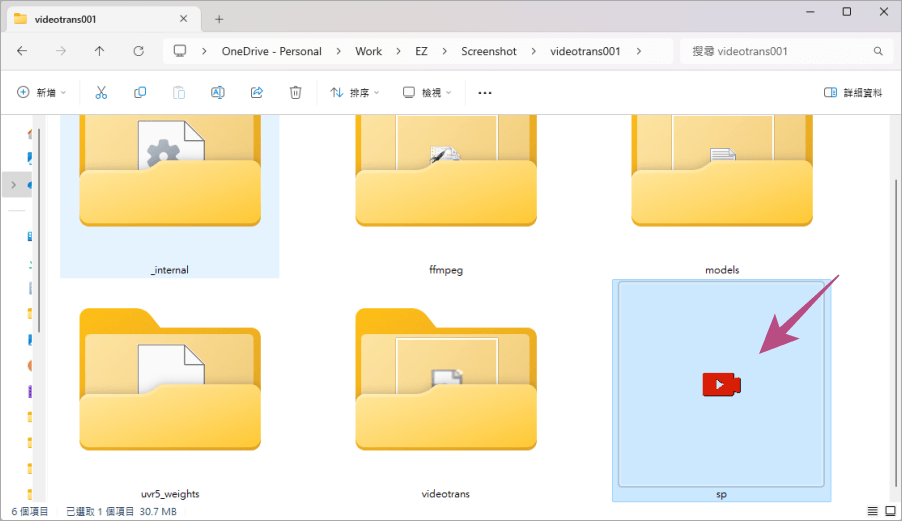 解壓縮之後,大小總共超過 5GB,各位記得將壓縮檔解壓縮在全英文的路徑下,否則可能會沒有辦法執行。解壓縮完成之後,點上圖中的 SP 圖示來啟動應用程式,如果你點擊下去發現沒有反應,可能要等待一段時間之後才會啟動。
解壓縮之後,大小總共超過 5GB,各位記得將壓縮檔解壓縮在全英文的路徑下,否則可能會沒有辦法執行。解壓縮完成之後,點上圖中的 SP 圖示來啟動應用程式,如果你點擊下去發現沒有反應,可能要等待一段時間之後才會啟動。 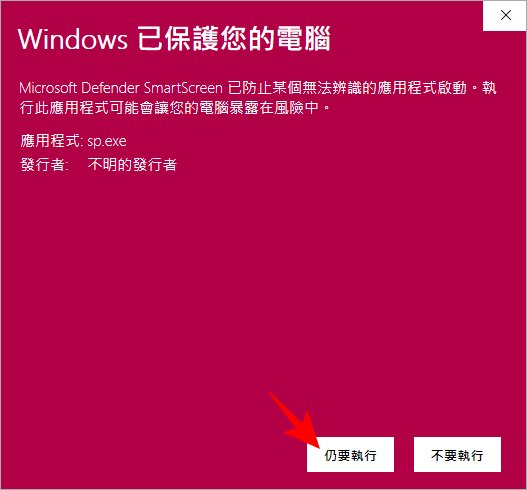 看到上方的畫面是正常的,因為是從非微軟官方商店下載的應用程式,就會出現上方的警告畫面,直接點擊仍要執行。
看到上方的畫面是正常的,因為是從非微軟官方商店下載的應用程式,就會出現上方的警告畫面,直接點擊仍要執行。 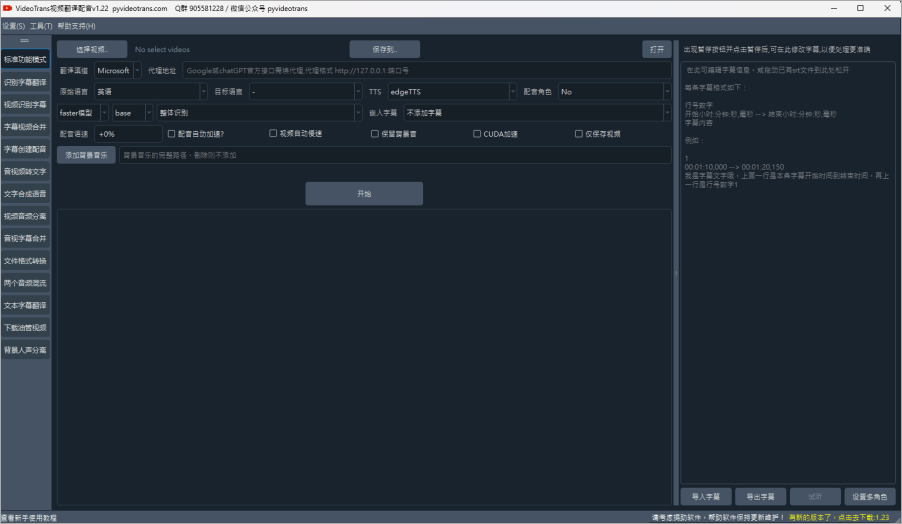 這個介面看起來有點可怕,不過其實沒有看起來得這麼複雜,下面小編一一為大家拆解。主要功能全部都在視窗左側,包含:
這個介面看起來有點可怕,不過其實沒有看起來得這麼複雜,下面小編一一為大家拆解。主要功能全部都在視窗左側,包含: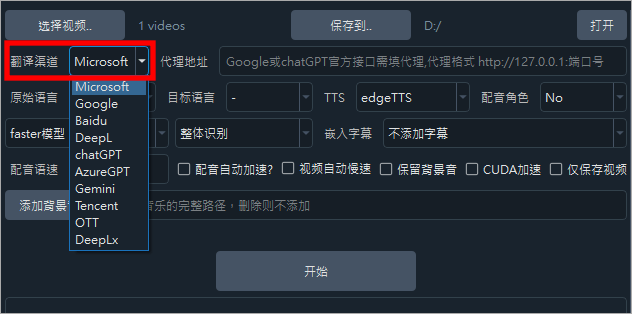 首先點擊上方的選擇視頻來載入影片,然後右邊的「保存到」是儲存的路徑,先設定好這 2 個項目之後選擇「翻譯渠道」。預設是 Microsoft 翻譯引擎是免費的,所以我們用預設的 Microsoft 即可,如果你有 Google 或是 chatGPT,就需要額外的設定才可以使用。
首先點擊上方的選擇視頻來載入影片,然後右邊的「保存到」是儲存的路徑,先設定好這 2 個項目之後選擇「翻譯渠道」。預設是 Microsoft 翻譯引擎是免費的,所以我們用預設的 Microsoft 即可,如果你有 Google 或是 chatGPT,就需要額外的設定才可以使用。 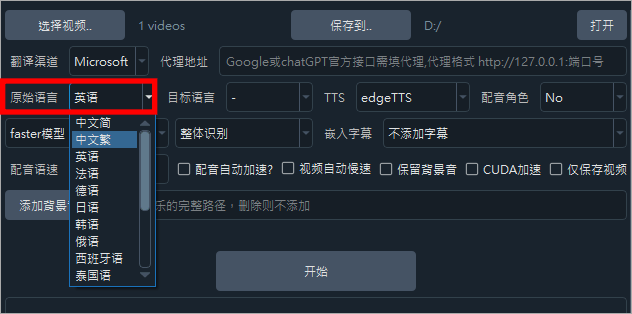 接著我們選擇影片的原始語言,通常都是中文繁體,我們直接選擇中文繁體就可以了。
接著我們選擇影片的原始語言,通常都是中文繁體,我們直接選擇中文繁體就可以了。 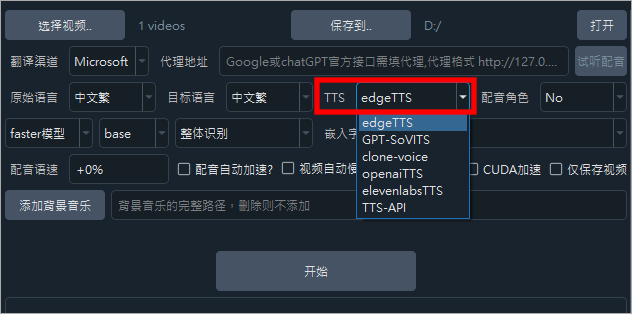 接下來是輸出的語言,如果你要把中文轉換成其他語言輸出語言,可以選擇簡繁、英語、韓語、西藏語、土耳其語、克拉克語、德語、土耳其語、西班牙語、支援葡萄牙語、越南語、泰國語、阿拉伯語、土耳其語、匈牙利語、印度語等等...,再來就是 TTS 語音轉文字的引擎,預設是 edge TTS,如果你有其他偏好,也可以選擇下方。一共有六種語音轉文字引擎。
接下來是輸出的語言,如果你要把中文轉換成其他語言輸出語言,可以選擇簡繁、英語、韓語、西藏語、土耳其語、克拉克語、德語、土耳其語、西班牙語、支援葡萄牙語、越南語、泰國語、阿拉伯語、土耳其語、匈牙利語、印度語等等...,再來就是 TTS 語音轉文字的引擎,預設是 edge TTS,如果你有其他偏好,也可以選擇下方。一共有六種語音轉文字引擎。 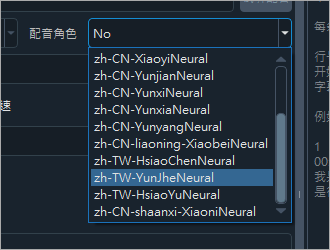 配音也有支援繁體中文,繁中有 3 種不同的音色。配音指的是翻譯之後的配音,舉一個具體的例子,比如我的影片要中翻英,這個配音指的就是英文的聲音。
配音也有支援繁體中文,繁中有 3 種不同的音色。配音指的是翻譯之後的配音,舉一個具體的例子,比如我的影片要中翻英,這個配音指的就是英文的聲音。 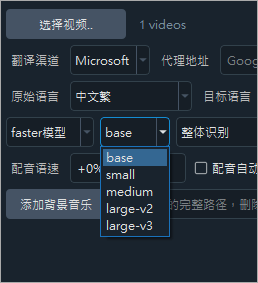 最後選擇 faster 模型或 openAI 模型,用預設的 faster 模型即可,然後再選擇 base、small、medium、large-v2、large-v3,越後面的選項,辨識效果越來越好,但辨識速度越來越慢,所需記憶體越來越大,內建 base 模型,其他模型請單獨下載後,解壓縮放到 /models 目錄下,如果 GPU 低於 4GB,請勿使用 large-v3
最後選擇 faster 模型或 openAI 模型,用預設的 faster 模型即可,然後再選擇 base、small、medium、large-v2、large-v3,越後面的選項,辨識效果越來越好,但辨識速度越來越慢,所需記憶體越來越大,內建 base 模型,其他模型請單獨下載後,解壓縮放到 /models 目錄下,如果 GPU 低於 4GB,請勿使用 large-v3 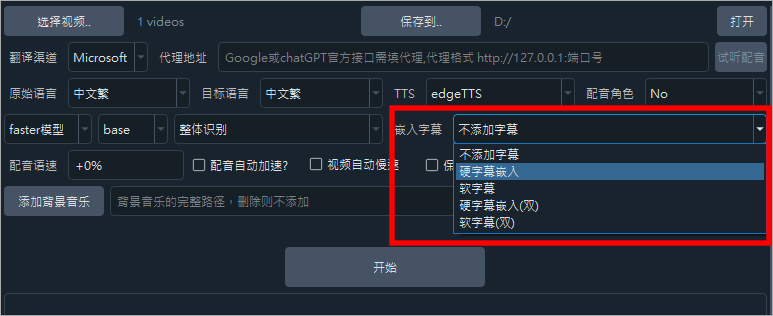 硬字幕是直接把辨識出來的字幕壓在影片上,軟字幕則是輸出 SRT 方便日後可以再編輯。
硬字幕是直接把辨識出來的字幕壓在影片上,軟字幕則是輸出 SRT 方便日後可以再編輯。 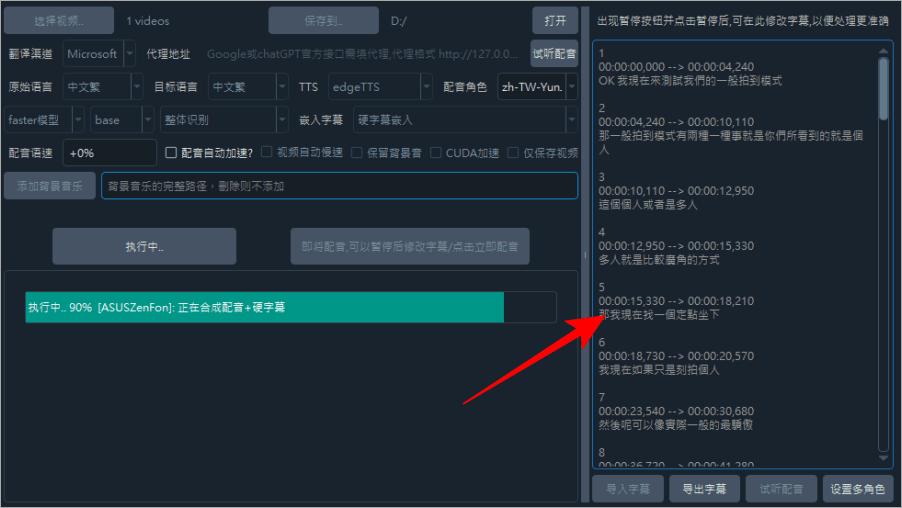 最後按下開始就會開始就會開始辨識字幕,如果你電腦有顯卡可以把 CUDA 加速勾起來,速度會快很多,否則用 CPU 去跑會比較吃力。等待一段時間後,就可以看到字幕辨識完成出現在右側囉。
最後按下開始就會開始就會開始辨識字幕,如果你電腦有顯卡可以把 CUDA 加速勾起來,速度會快很多,否則用 CPU 去跑會比較吃力。等待一段時間後,就可以看到字幕辨識完成出現在右側囉。 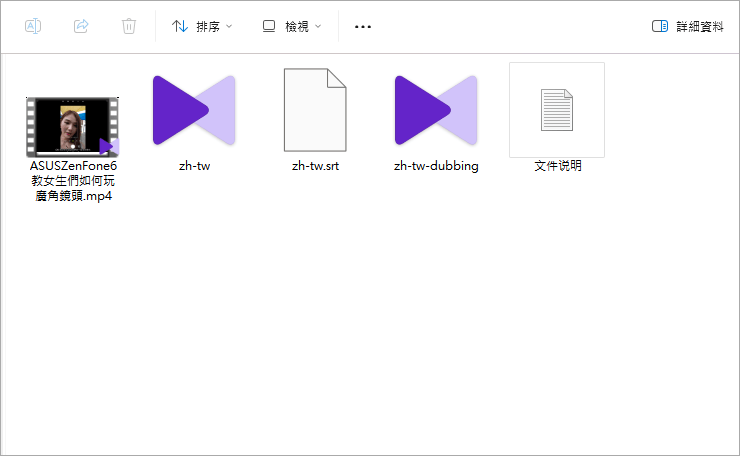 接著打開我們剛剛指定的資料夾,就可以看到檔案,有影片檔、字幕檔、配音檔。效果放在下方給各位看看。
上方是小編載入的原始影片
這個是 AI 處理過後的影片,小編是直接中文改中文,繁中配音不錯,不會有中國腔調,不過影片的嘴型會對不上,因為嘴型沒有修改,但用來處理影片翻譯是滿快速的方案,而且是免費的,連結小編整理在下方,請立即收下試試吧!下載:
接著打開我們剛剛指定的資料夾,就可以看到檔案,有影片檔、字幕檔、配音檔。效果放在下方給各位看看。
上方是小編載入的原始影片
這個是 AI 處理過後的影片,小編是直接中文改中文,繁中配音不錯,不會有中國腔調,不過影片的嘴型會對不上,因為嘴型沒有修改,但用來處理影片翻譯是滿快速的方案,而且是免費的,連結小編整理在下方,請立即收下試試吧!下載:


