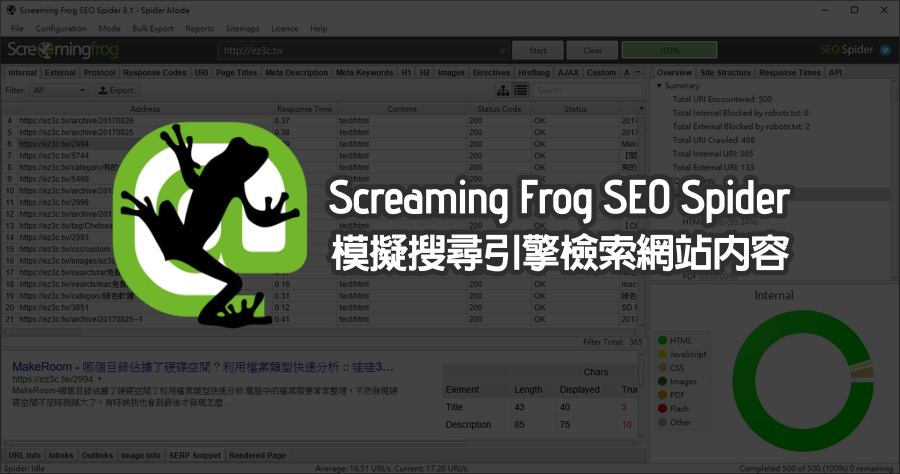
Crawl data from website
CommonCrawlmaintainsafree,openrepositoryofwebcrawldatathatcanbeusedbyanyone.CommonCrawlisa501(c)(3)non–profitfoundedin2007.,2022年3月23日—WebcrawlingreferstotheprocessofextractingspecificHTMLdatafromcertainwebsitesbyusingaprogramorautomatedscript...
Web Crawler in Python: Step-by
- How to write a web crawler
- web crawler comparison
- screaming frog
- download website tool
- octoparse下載
- web crawler下載
- crawler software
- Octoparse web crawler
- web crawler tool
- Sitebulb
- web crawler tool
- copy website
- import io
- web crawler中文
- website crawler tool
- web crawler中文
- free web crawler tool
- web crawler
- Web Scraper download
- Site crawler
- free web crawler
- dexi io
- how to crawl a website
- screaming frog
- web crawler下載
2023年7月19日—It'saPythonscriptthatexplorespages,discoverslinks,andfollowsthemtoincreasethedatayoucanextractfromrelevantwebsites.Search ...
** 本站引用參考文章部分資訊,基於少量部分引用原則,為了避免造成過多外部連結,保留參考來源資訊而不直接連結,也請見諒 **

